Slurm accounting logs
The Slurm job scheduler allows the collection of accounting information for every job (including job steps) executed on your HPC cluster, storing it in a relational database. To keep this data after job completion, CCME automatically enables Slurm accounting.
With this feature, you gain access to operational details concerning running, terminated, and completed jobs. Additionally, you can establish quality of service levels for specific jobs, partitions, and users, as well as implement fair-share scheduling.
Slurm accounting provides the capability to monitor and limit resource consumption. Moreover, it enables the generation of comprehensive usage reports, which prove beneficial for billing and analysis of usage efficiency.
CCME deploys a MariaDB database on the HeadNode of the cluster, and configures Slurm to report accounting information about the jobs in this database.
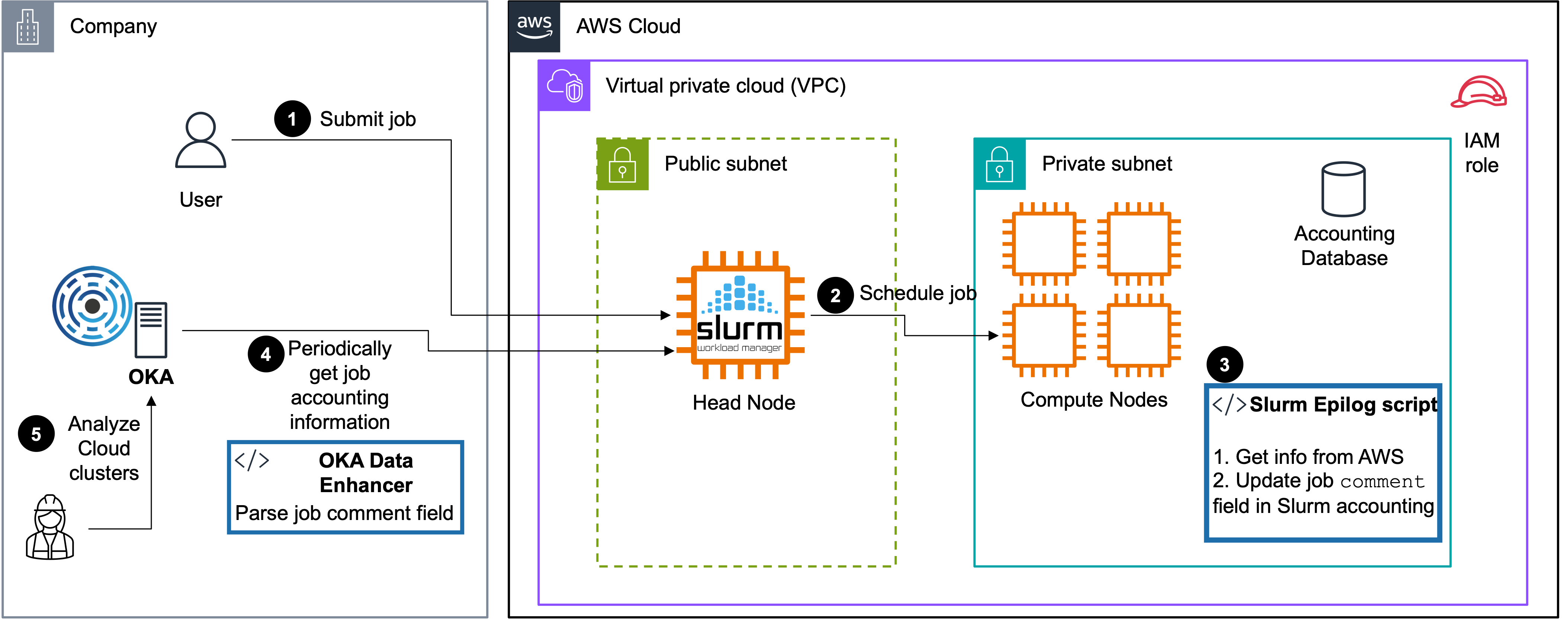
On top of the standard metrics gathered by Slurm, CCME configures a Slurm epilog script that will gather information about the AWS environment on which the jobs run, and store this information as comma separated values (CSV) in the Comment field of the jobs. The gathered information are:
instance type
instance id of the “main” job node
availability zone
region
instance price
cost type: ondemand or spot
tenancy: shared, reserved…
This Slurm epilog script retrieves information about the instance type and its pricing when the job ends,
and stores the information in the Comment field of the job in sacct.
The user provided comments are kept, and the information are added at the end after a semicolon.
The format of the Comment field is the following:
:PricingInfo=${instance type};${instance id};${availability zone};${region};${instance price};${cost type};${tenancy}
All the accounting information are then available through the sacct command line. You can then post-process them, or simply import the accounting logs in OKA (the integration of CCME logs and OKA is documented in the OKA online documentation).
On top of accessing the logs through sacct, you can also directly find the accounting logs exported daily (and also whenever the
HeadNode is stopped/rebooted/terminated) in the
CCME_JSLOGS_BUCKET (which can be configured in ParallelCluster configuration file under the HeadNode.CustomActions.OnNodeStart.Args parameter).
By default, this parameter is set to CCME_DATA_BUCKET in the example configuration files created by the CMH.